

1. 연구 동기 (Motivation & Contribution)
Dreambooth는 2023년 CVPR에 등재된 Google Research에서 작성된 논문으로, Image Personalization task를 다룸.
•
Image Personalization
특정 subject(ex. teddybear)의 identity를 유지하면서 다양한 deformation(ex. sleeping, walking)을 적용해 이미지를 생성하는 분야
•
Contribution
1.
few shot image(5장 내외)로 특정 subject에 대해 이미지 생성모델을 fine-tuning 가능
2.
fine-tuning된 모델을 사용하여 다양한 scene, pose, view 등으로 확장하여 이미지 생성 가능
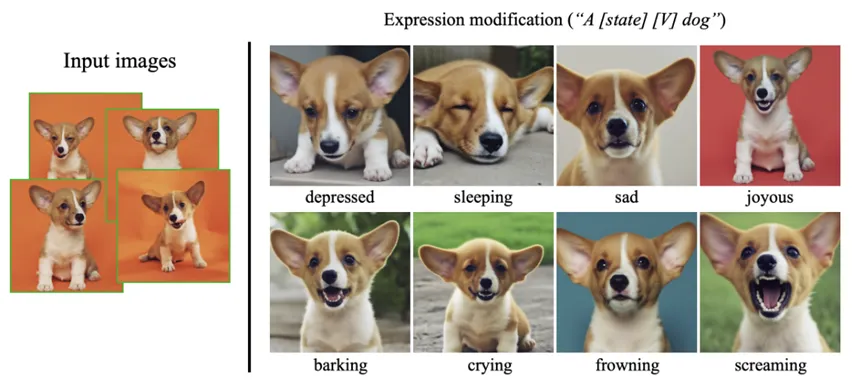
Expression에 대해 personlization한 결과

Scene에 대해 personalization한 결과
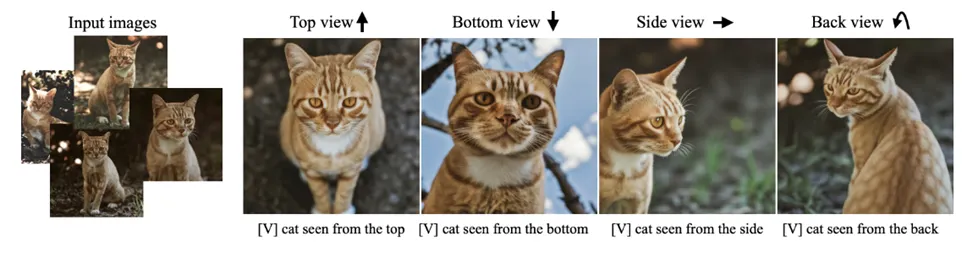
Viewpoint에 대해 personalization한 결과
이전 모델 Prompt-to-prompt, Textual Inversion의 한계를 극복하면서, identity 보존도와 deformation 다양성 부분에서 모두 우수한 결과를 보여줌.
2. 배경 소개 (Background & Related Works)
2.1 기존 Image Editing 모델들의 한계
2.1.1 Prompt-to-Prompt (2022, Google Research)
•
텍스트에 따른 deformation을 어느 정도 수행할 수 있으나, 복잡한 deformation을 수행하기 어려움.
•
ex) 단순히 음료나 선글라스를 바꾸는 정도는 가능하나, ‘곰이 뛰거나 일어서는 자세’ 같은 역동적인 변형은 불가능.

Prompt-to-Prompt의 inference 예시
2.1.2 Textual Inversion (2022, NVIDIA)
•
다양한 deformation이 가능하나, input subject의 identity을 충분히 보존하지 못한다는 단점이 있음.
•
ex) 백팩을 메거나 배를 타는 등의 변화는 가능하지만, 원본 주체의 형태나 특징이 흐려지는 문제가 존재.

Textual Inversion의 inference 예시
DreamBooth는 위 두 모델의 장점을 결합하고 단점을 보완하여, identity를 유지하면서 동시에 다양한 deformation을 적용할 수 있는 image personalization task의 foundation model로 주목 받음.

Textual Inversion과 비교했을 때 Dreambooth의 결과
2.2 Diffusion
•
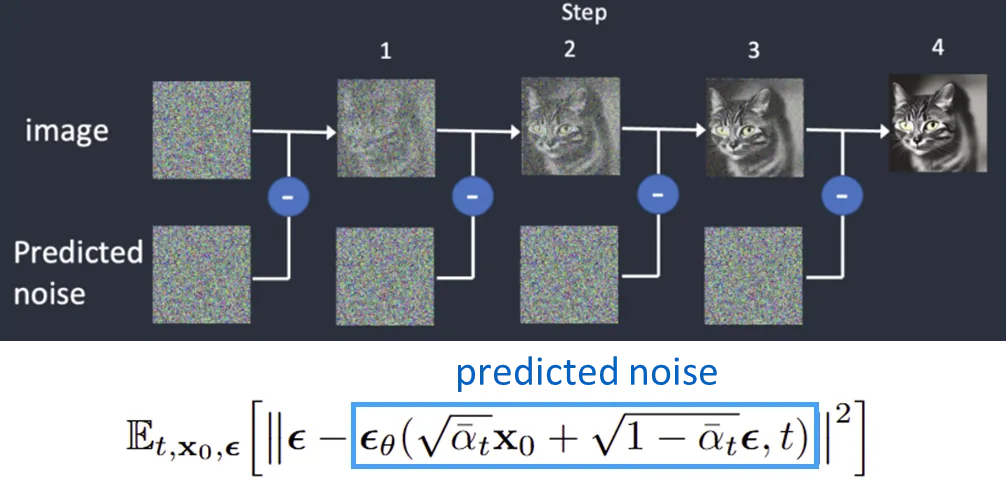
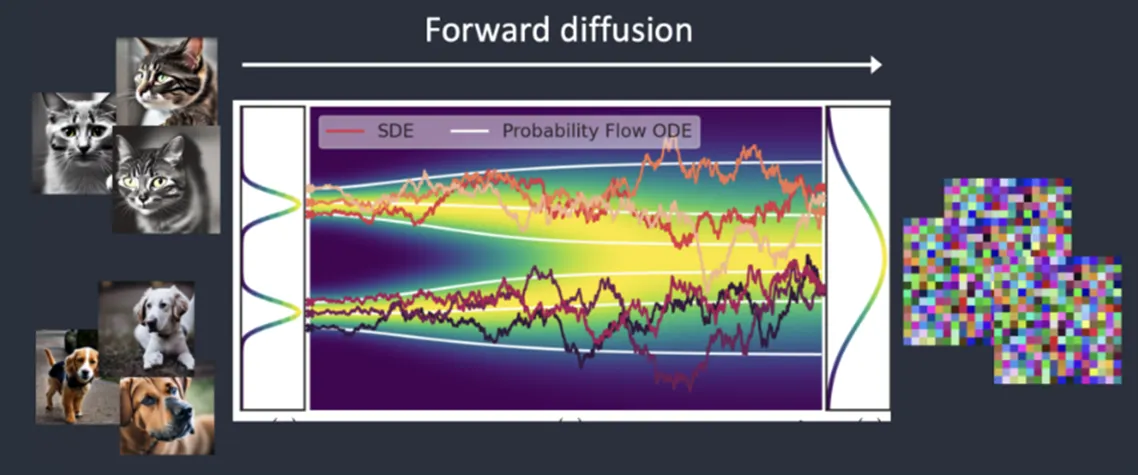
이미지에 노이즈를 점진적으로 추가(Forward Process)하고, 이를 제거(Reverse Process)하는 과정을 학습.
•
학습 시에는 각 단계별로 ‘이미지에 더해진 노이즈’를 예측하도록 UNet 등과 같은 모델을 훈련하며, L2 노이즈 예측을 위한 손실 함수를 사용.
•
DDPM에서는 Markovian Process을 적용해 복잡했던 diffusion objective function을 단순한 노이즈 예측 L2 손실로 치환하여 학습을 크게 단순화함.
2.3 Stable Diffusion(= Latent Diffusion)
•
고해상도 이미지를 직접 픽셀 단위로 학습하면 차원이 매우 커(ex 512×512×3) 연산이 비효율적.
•
Stable Diffusion에서는 이미지를 인코더(Encoder)로 압축한 latent space에서 diffusion을 수행하고, 디코더(Decoder)를 통해 최종 이미지를 복원.
◦
이때 Encoder, Decoder로 VAE를 사용.
•
텍스트 정보는 UNet의 각 레이어에 있는 Cross-Attention 블록을 통해 주입되어, 텍스트 조건(text condition)에 따른 이미지 생성이 가능해짐.
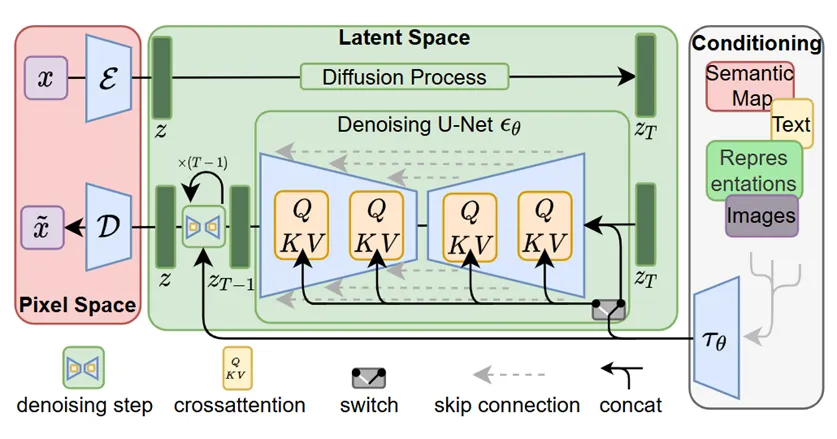
Stable Diffusion architecture

3. 방법론 (Methodology)
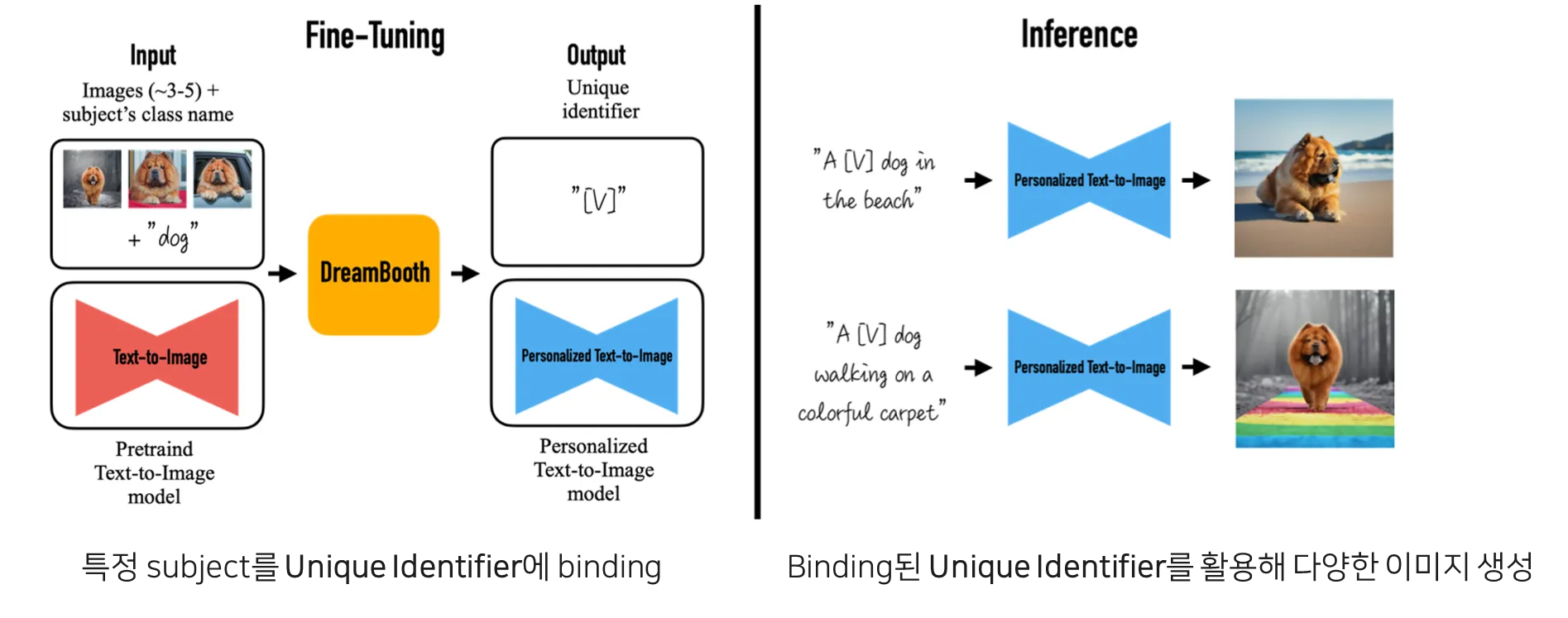
Dreambooth의 전반적인 structure
3.1 Fine-tuning으로 Unique Token 학습
•
Fine-tuning 시, 학습시키고 싶은 subject의 이미지 5장 내외 + “A [Unique identifier] [Class noun]" (ex. “A sks dog") 형태로 텍스트를 넣어줌.
•
“sks"는 실제 언어에는 없는 unique한 identifier로, 이것이 특정 subject의 identity를 압축적으로 담는 token이 됨.
3.2 Reconstruction Loss
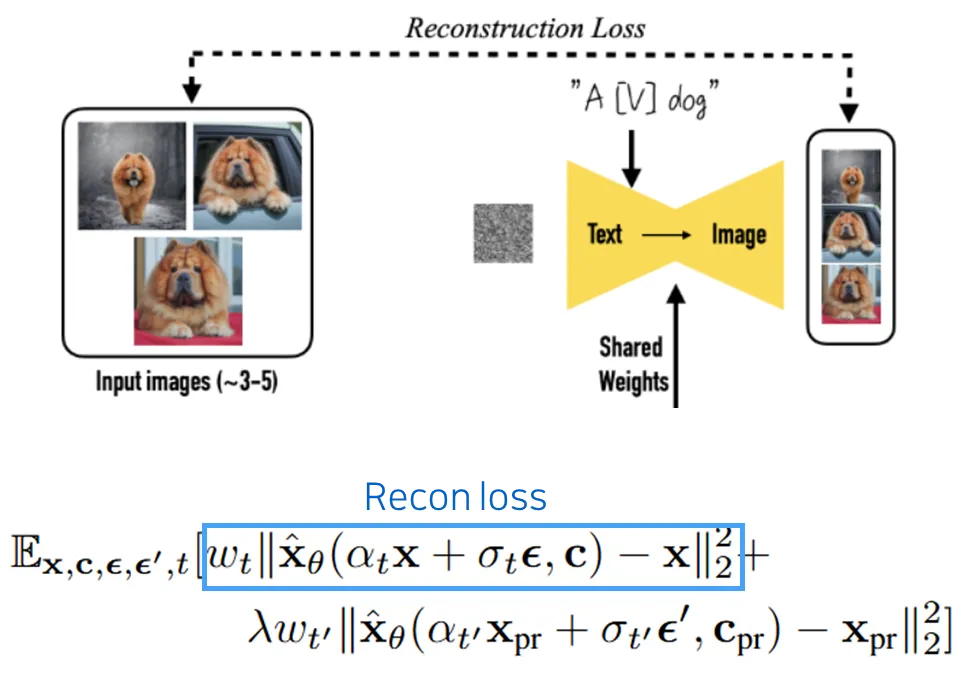
•
Fine-tuning 시, 모델은 input 이미지를 reconstruction하는 과정을 통해, “sks”와 “dog”가 함께 표현된 이미지를 예측.
•
이를 통해 “sks dog”라는 token 조합이 input subject의 identity를 모델 내부에 학습하도록 유도함.
3.3 Prior Preservation Loss
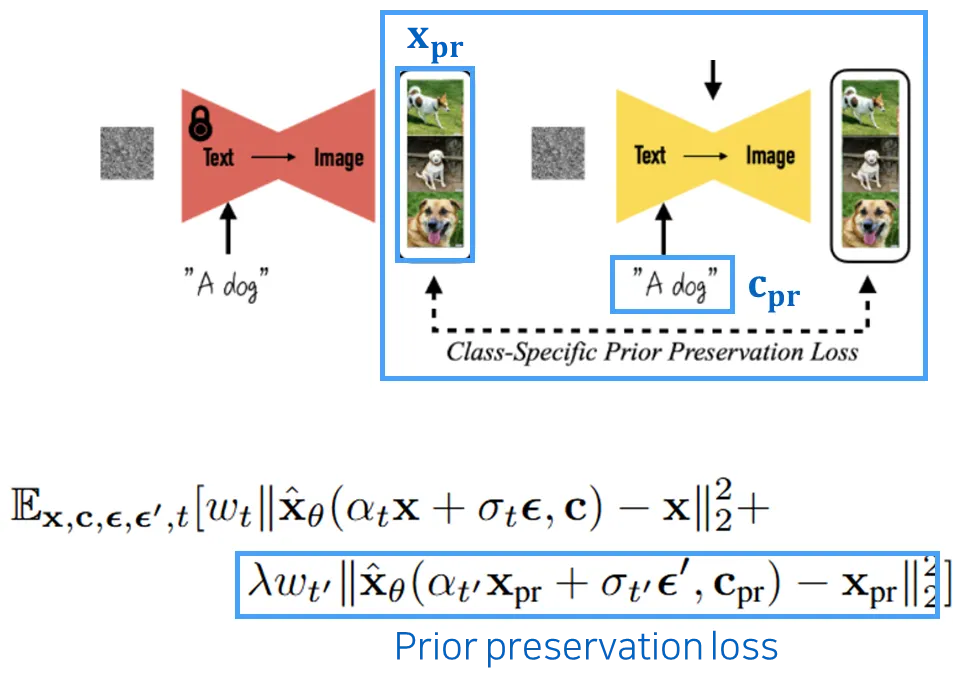
•
Reconstruction Loss만 사용할 경우, 모델이 “dog”라는 일반 개념을 잃어버리고 input된 특정 “sks dog"에만 overfitting되는 문제가 발생할 수 있음.
•
이를 방지하기 위해, 모델이 자체적으로 생성한 ”class 이미지”(ex. “A dog”을 input으로 줬을 때 생성되는 이미지)를 reconstruction하는 추가적인 손실을 줌 (Prior Preservation).
•
이렇게 하면 모델이 “dog”에 대한 Prior knowledge를 잃지 않고 유지할 수 있음.
•
λ(람다) 값으로 Reconstruction Loss와 Prior Preservation Loss 간의 학습 강도를 조절함.
4. 실험 결과 및 분석 (Experiments & Results)
4.1 Comparison with detailed prompting
•
Imagen과 DALLE-2의 경우
“retro style yellow alarm clock with a white clock face
and a yellow number three on the right part of the clock face in the jungle”
•
위의 text를 넣어 이미지들을 생성함.

•
Dreambooth는 detail한 prompt없이 몇 장의 사진과 간단한 text만으로 consistent하면서 input subject의 identity를 보존하여 다양한 이미지 생성 가능함.
4.2 Quantitative Results
4.2.1 Subject Fidelity and Prompt Fidelity


•
30개 subject * 25개 prompt * 4개의 image = 3000개 image 에 대해서 metric 수치 측정
•
DINO : generated image와 real image간의 cosine sim avg
•
CLIP-I : generated image와 real image간의 cosine sim avg
•
CLIP-T : prompt와 generated image 간의 cosine sim avg
◦
DINO, CLIP-I는 Subject Fidelity를 측정, CLIP-T는 Prompt Fidelity를 측정
•
Dreambooth가 Textual Inversion model보다 Subject Fidelity, Prompt Fidelity 모두 좋은 수치를 보임.
4.3 Qualitative Results
4.3.1 Live Subject Personalization results

4.3.2 Object Personalization results

4.3.3 Accessorication results

4.4 Ablation Study
4.4.1 Prior Preservation loss ablation

•
prior preservation loss를 적용시켰을 때 input subject에 fitting되지 않고 다양한 결과가 생성됨
4.4.2 Class name ablation
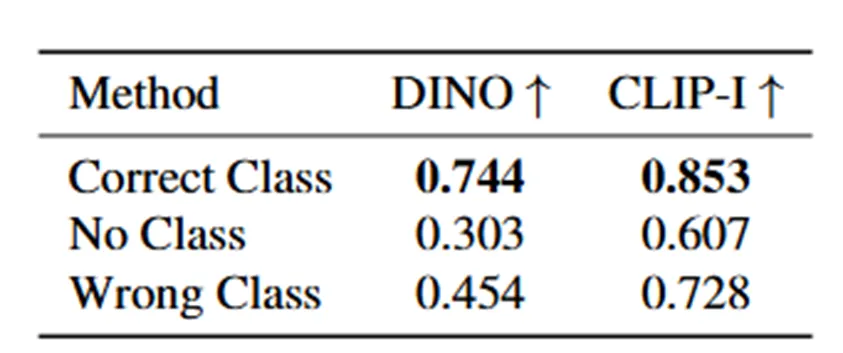
<Prompt text>
“A [Identifier] [Correct class noun]”
“A [Identifier]”
“A [Identifier] [Wrong class noun]”
•
Subject에 대한 정확한 Class noun을 prompt에 넣어 같이 학습할 때 Subject Fidelity가 가장 높음.
5. 결론 (Conclusion)
5.1 Limitation

1.
Context(ex. ISS, moon)에 대한 prior가 부족한 경우
⇒ Context가 잘 생성되지 않음
2.
Context와 input identity가 잘 분리되지 않은 경우
⇒ Context에 의해 identity가 훼손되어 생성됨
3.
Prompt가 input image의 setting과 유사한 경우
⇒ Input image와 동일하게 생성됨
5.2 Conclusion
5.2.1 Summary

•
Learnable token을 통해 few shot으로 model을 원하는 subject에 fine tuning 가능
•
Prior preservation loss를 추가해 다양한 deformation 생성 및 input에 대한 overfitting 방지
•
구체적인 textual description없이도 원하는 subject에 대한 이미지 생성 가능
•
기존의 방식보다 deformation 능력이 뛰어나고, identity 보존도 뛰어남
5.2.2 Further Study

•
Dreambooth는 Image personalization task의 근간이 되었음
•
현재는 model을 따로 학습시키지 않고 tuning-free로 한 장의 input image만으로도 personalization이 가능하며,
•
단순한 subject 뿐만 아니라 복잡한 human identity에 대해서도 personalization 가능
참고자료
•
Ruiz, Nataniel, et al. "DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation”
•
Hertz, Amir, et al. "Prompt-to-prompt image editing with cross attention control.”
•
Gal, Rinon, et al. "An image is worth one word: Personalizing text-to-image generation using textual inversion.“
•
Ho, Jonathan, Ajay Jain, and Pieter Abbeel. "Denoising diffusion probabilistic models.”
•
Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models.”
•
https://stable-diffusion-art.com/how-stable-diffusion-work/
