

1. 연구 동기 (Motivation & Contribution)

복잡한 실내 환경에서 현재 위치를 사진을 찍어 미리 가지고 있는 DB 3D scene 을 활용하여 찾는 것이 주 목적이다. 이 task 를 Coarse Visual Localization 이라 한다.

본 논문에서 제안한 concept은 query image 를 받아 DB 3D scene graph 의 modality를 cross 시키고 이를 통해 current position 을 찾는다.

이 방법은 novel한 방안을 제시한다. cross-modal을 이용해 localization을 하기에 robustness 하다. 또한 3D scene graph 라는 다양한 modality를 사용하여 새로운 방향 또한 제시한다.
2. 배경 소개 (Background & Related Works)

query image 와 db image 를 비교하여 장소를 찾는 것을 image retreival 이라 한다. 이는 정확도가 높고 구현이 간단하지만 환경 변화에 민감하고 메모리를 많이 차지한다는 단점이 있다.

image뿐 아니라 다양한 modality 를 비교하여 localization 하는 기존 방법이 있다. semantic 정보를 가져오기에 환경 변화에 robust 하다는 장점이 있지만 viewpoint 가 달라지면 robust 하지 않고 single modality 를 사용한다는 단점이 있다.
3. 방법론 (Methodology)
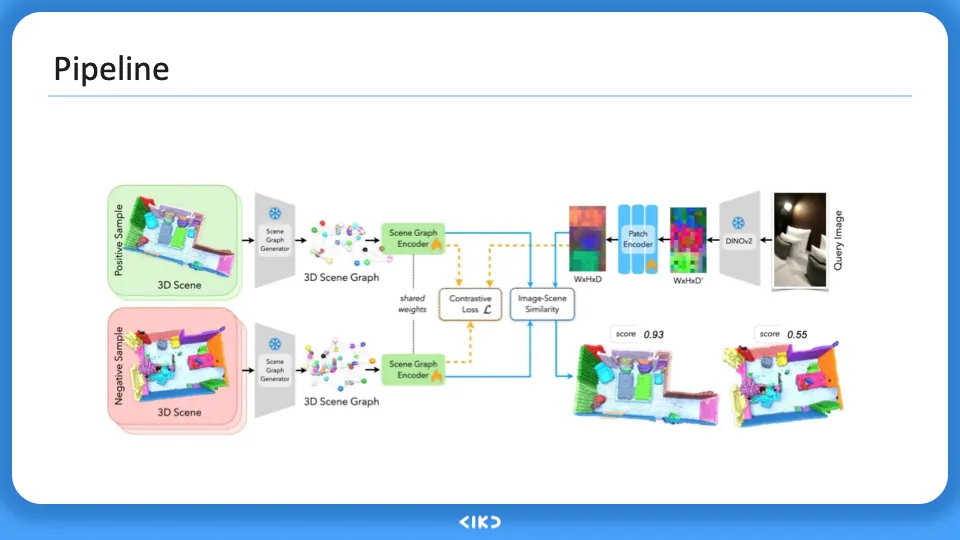
전체적인 training, inference pipeline은 위와 같다.
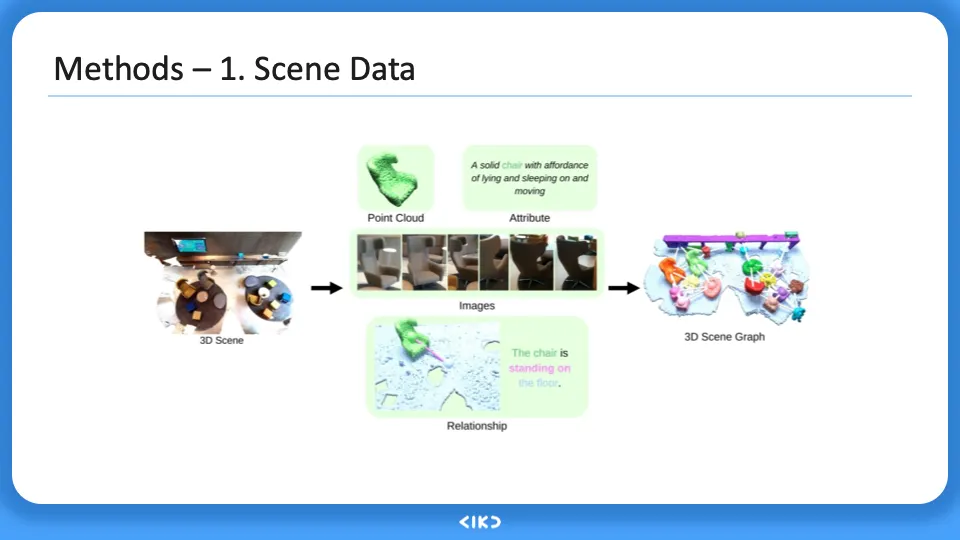
DB 에 존재하는 3d scene 을 활용하여 3D scene graph 를 만들어낸다. 여기에는 다양한 modality를 포함하며 point cloud, attribute, images, relationship, structure 이 존재한다.
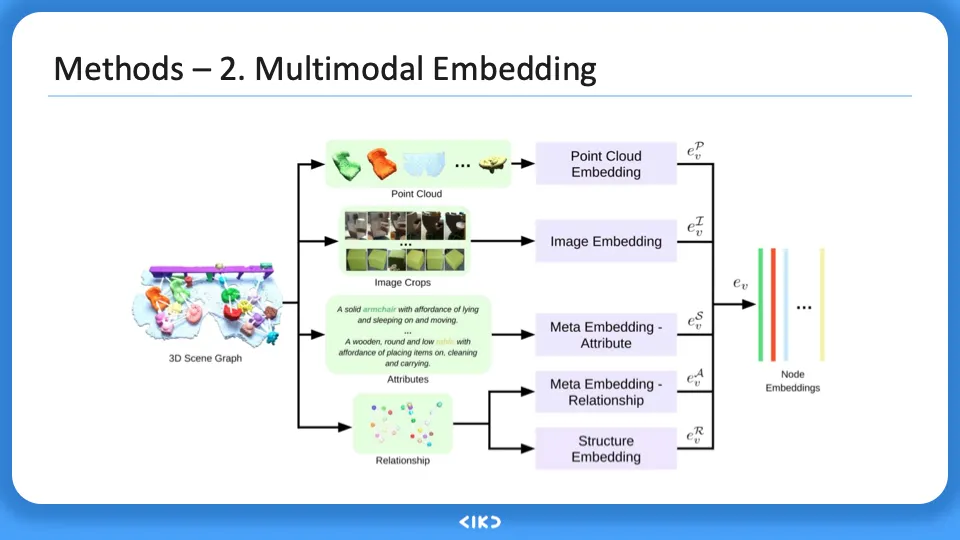
위 방법으로 얻은 3D scene graph 의 다양한 modality 를 각각 다른 방법으로 embeeding vector로 만든다. 이때 encoder가 사용되며 이를 training시킨다. 위 embedding들을 concatenation한다.
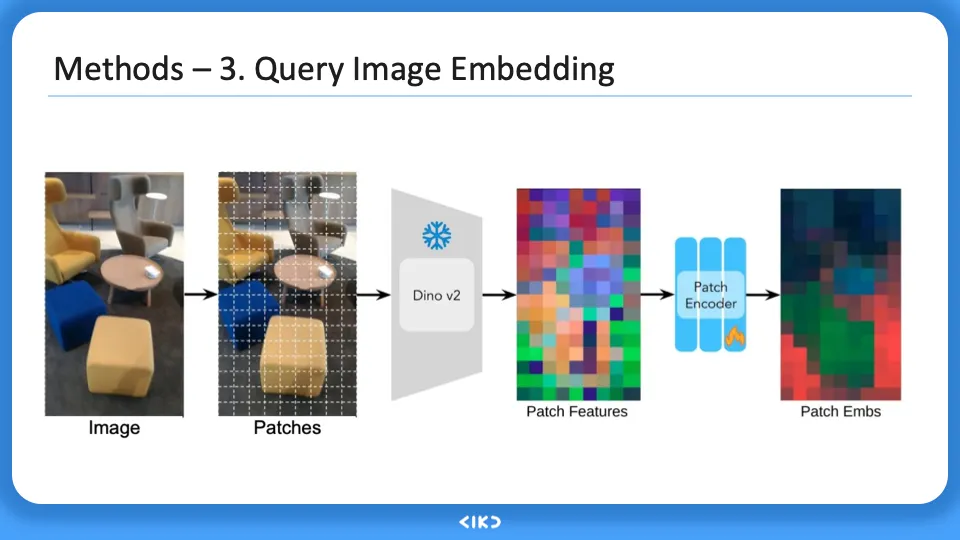
query image를 이제 embedding화 시킨다. image를 patch로 나누고 feature을 뽑아낸다. 이제 encoder를 사용해 embedding vector로 만든다. 이 encoder를 학습시키며 진행한다.
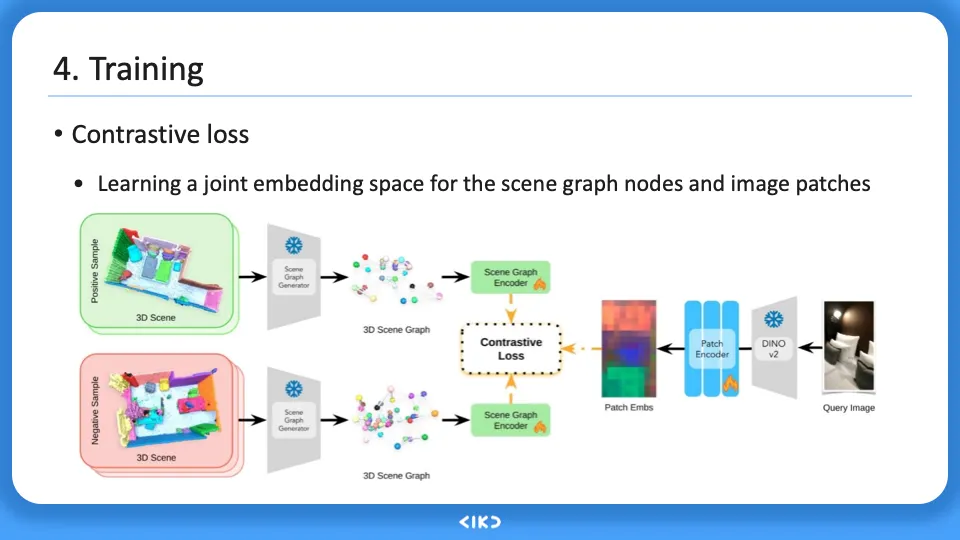
위에 봤던 데이터, embedding들을 이용해 contrastive learning을 하고 학습을 시켜 encoder를 업데이트한다.
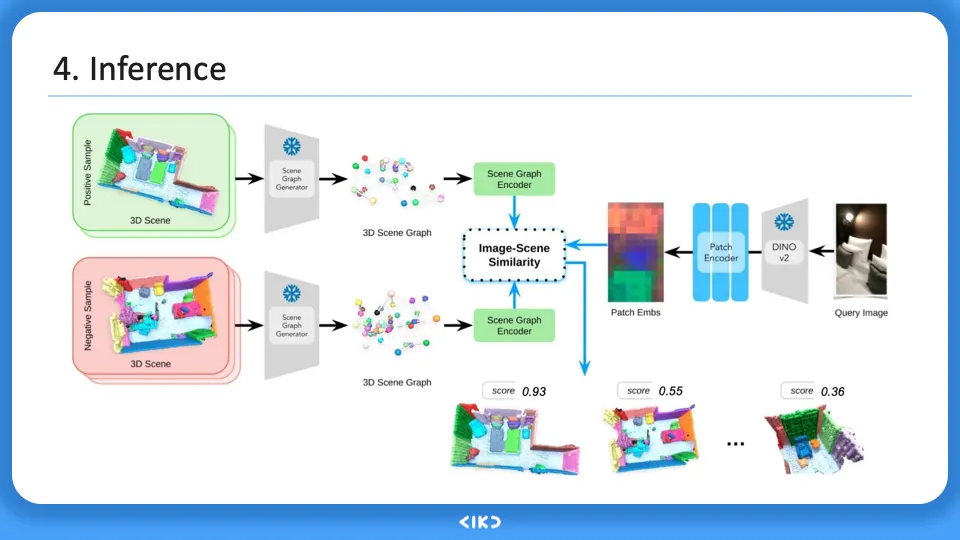
이제 inference에서는 query image를 DB에 있는 3d scene 들과 비교하고 가장 높은 cosine simlarity 점수를 가진 장소로 image-retrieval 한다.
4. 실험 결과 및 분석 (Experiments & Results)

3RScan 데이터셋은 indoor environment 의 3d scene을 다양한 각도, 시간에 따른 변화를 다 기록한다. 이를 실험에 사용하게 된다.
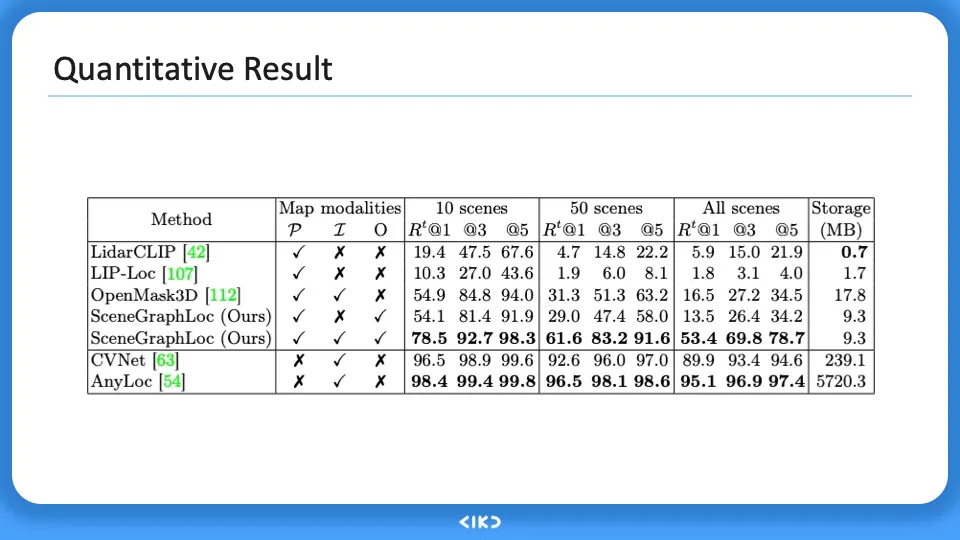
정량적 실험결과에서는 다른 single-modal 모델과 비교를 했으며 이와 비교했을때 성능면에서 훨씬 좋은 결과를 내었고 메모리, 처리시간 면에서도 유리한 것을 확인하였다.

정성적 실험결과에서는 query image 내에서 다양한 object가 포착되면 이를 patch 단계에서 구분을 하여 DB와 비교가 가능하다. 이런 장소 이미지는 좋은 결과를 내고 place recognition 이 우수하다.
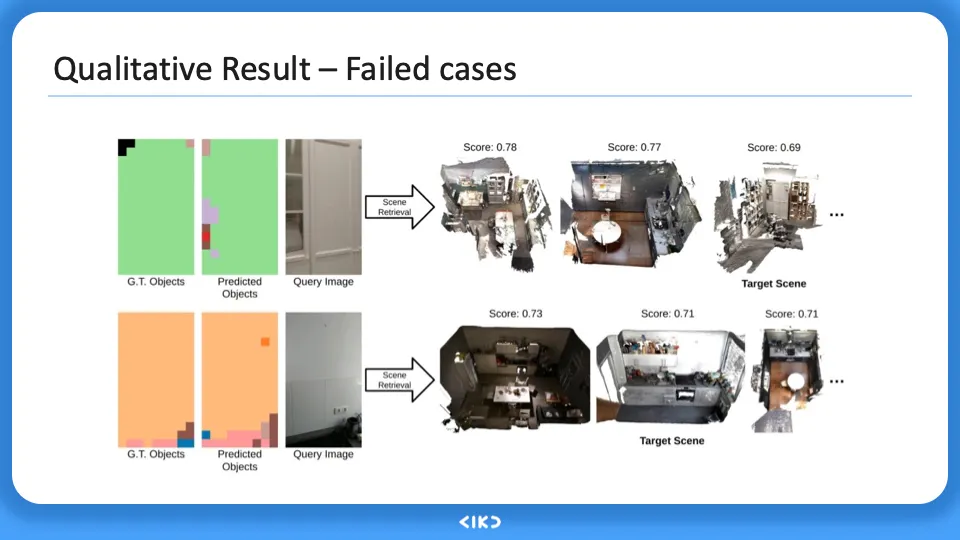
+이와 반대로 벽, 바닥과 같은 object가 따로 포착되지 않으면 cosine similarity 점수가 구분이 잘 안되었으며 결과가 좋지 못한 것을 확인하였다. object-level 에서 embedding 을 생성하기에 이런 한계가 존재하게 된다.
5. 결론 (Conclusion)

SceneGraphLoc 은 3d scene 을 다양한 modality 를 활용하여 image-retrieval 을 좋은 성능을 보이며 수행하였다. 그 과정에서 높은 정확도, 적은 메모리 요구, 빠른 처리시간 등 다양한 장점이 존재한다.
