

FeatUp: A Model-Agnostic Framework for Features at Any Resolution
ICLR 2024에 Accept된 논문으로, 아카이브에 3월 15일에 올라온 따끈따끈한 논문입니다.
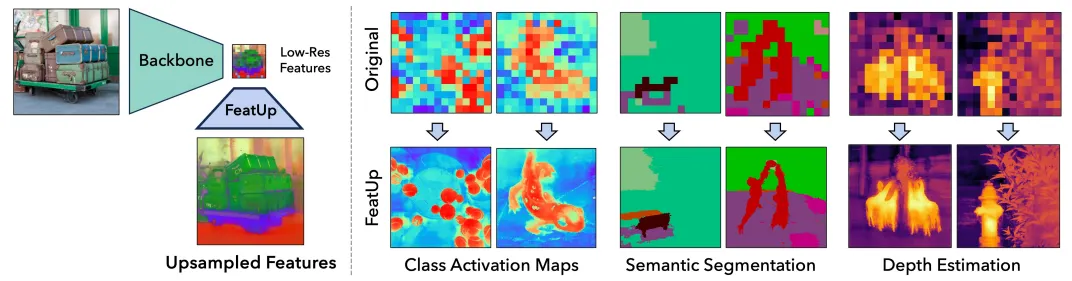
CV에서 모델의 성능이 저하될 수 밖에 없는 요인인 feature들의 low resolution 문제를 해결하고자 한 논문이고, Deep feature에서 손실된 spatial한 정보들을 Model-Agnostic하게 reconstruct하는 방법을 크게 두가지로 제시합니다.
또한 해당 방법론을 사용했을 때 Semantic segmentation, Depth estimation 등의 downstream task들에서 훌륭한 성능을 달성할 수 있음을 보여줍니다.
Feature Extraction

딥러닝과 머신러닝의 가장 큰 차이점은 바로 “feature”에 있습니다. 머신러닝에서는 인간이 직접 수동으로 중요한 feature를 선택하는 feature engineering 과정이 중요했다면. 딥러닝 시대에 들어서고 모델이 더욱 깊어지면서 모델이 중요한 feature들을 스스로 찾아낼 수 있는 능력을 갖추게 되었습니다.
이러한 Deep Feature들 덕분에 딥러닝 기반의 여러 모델, 알고리즘들이 성공을 거두었지만, 이러한 feature들은 semantic quality를 위해서 spatial resolution을 희생해야만 했습니다.
예를 들어, ResNet은 224x224 사이즈의 이미지에 대해 7x7 사이즈의 deep feature를 생성하고, 이를 downstream task들에 사용합니다. 이는 pixel-wise로 dense한 예측이 이루어지는 segmentation이나 depth estimation을 해당 feature만 가지고 하는 것이 힘든 이유 중 하나이기도 합니다. 이러한 문제는 비단 ResNet뿐만의 문제가 아니라, 거의 모든 vision model들이 가지고 있는 문제점이기도 합니다.
이 논문의 저자들은 이러한 문제를 해결하기 위해, 어떤 모델이던지에 상관없이(model-agnostic) feature가 가지고 있는 원래의 의미나 방향을 바꾸지 않고, feature의 resolution을 향시킬 수 있는 새로운 framework를 제안하며, 이를 위해 NeRF의 3D Reconstruction framework에서 영감을 받았습니다.
Writer
•
AIKU 0기
•
고려대학교 켬퓨터학과 23학번
