
목차
문제 정의
당신은 이런 명언을 들어본 적이 있나요?

주식 투자자들의 명언, “소문에 사서 뉴스에 팔아라”.
이 명언은 좋은 소식이 들릴 때 주식을 매수해서 실제 그 일이 사실로 밝혀졌을 때 매도하라는 뜻을 가지고 있습니다. 즉, 뉴스에서 보도하기 시작하면 고점이라는 뜻이죠.
확실히 명언은 명언인지 많은 연구자들이 머신러닝과 딥러닝을 활용해 뉴스 데이터와 주가의 관계에 대한 연구를 지속적으로 해온 것을 확인할 수 있었습니다. 저희도 마찬가지로 뉴스 내용을 기반으로 주식 가격을 예측하는 모델에 관심을 가졌습니다.
여기서 잠깐, 비트코인은 어떨까요? 비트코인도 뉴스와 같은 텍스트 데이터에 영향을 받을까요?
… 그래서 사요?  프로젝트는 텍스트 데이터로 비트코인 가격을 예측하는 모델을 만들어보자는 아이디어에서 출발했습니다. 저희의 모델은 뉴스 및 텍스트와 10일 간의 장내 주식 거래 데이터를 이용해 10일 이후 가격 변동폭을 예측합니다. 모델은 Transformer 아키텍처와 BERT 기반 모델을 기반으로 합니다.
프로젝트는 텍스트 데이터로 비트코인 가격을 예측하는 모델을 만들어보자는 아이디어에서 출발했습니다. 저희의 모델은 뉴스 및 텍스트와 10일 간의 장내 주식 거래 데이터를 이용해 10일 이후 가격 변동폭을 예측합니다. 모델은 Transformer 아키텍처와 BERT 기반 모델을 기반으로 합니다.
프로젝트는 텍스트 데이터로 비트코인 가격을 예측하는 모델을 만들어보자는 아이디어에서 출발했습니다. 저희의 모델은 뉴스 및 텍스트와 10일 간의 장내 주식 거래 데이터를 이용해 10일 이후 가격 변동폭을 예측합니다. 모델은 Transformer 아키텍처와 BERT 기반 모델을 기반으로 합니다.선행 연구
금융, 블록체인, 텍스트 데이터를 결합하여 암호화폐 가격을 예측하는 딥러닝 모델을 제안한 논문  arXiv.orgForecasting Cryptocurrency Prices Using Deep Learning: Integrating... 에서는 Twitter-RoBERTa의 감성 분석과 BART-Large MNLI 모델을 활용하여 암호화폐 가격을 예측하고자 하였습니다.
arXiv.orgForecasting Cryptocurrency Prices Using Deep Learning: Integrating... 에서는 Twitter-RoBERTa의 감성 분석과 BART-Large MNLI 모델을 활용하여 암호화폐 가격을 예측하고자 하였습니다.
Visual Attention Model을 통해 비트코인 가격을 예측하는 연구 논문arXiv.orgVisual Attention Model for Cross-sectional Stock Return Prediction... 에서는 역사적 데이터를 큐브 모양으로 쌓아 데이터셋을 생성하고, 이를 입력으로 주는 어텐션 기반 모델을 제안했습니다.
데이터셋
데이터셋은 크게 암호화폐 차트 데이터와 텍스트 데이터로 구분할 수 있습니다.
암호화폐 차트 데이터
텍스트 데이터
텍스트 데이터는 비트코인 뉴스 데이터와 비트코인 관련 커뮤니티 텍스트 데이터로 구성되어 있습니다. 총 개수는 100만 개가 넘지만, 모델 학습을 고려하여 데이터셋의 일부를 샘플링하여 사용하였습니다.
비트코인 뉴스 데이터
가상화폐 전문 매체인 Cointelegraph, Coindesk 사이트에서 비트코인 키워드를 언급한 뉴스의 헤드라인을 크롤링하여 만들었습니다.
비트코인 커뮤니티 텍스트 데이터
모델
이 프로젝트의 모델은 하나의 기사/텍스트와 10일치 암호화폐 500여 종목의 차트 데이터를 입력으로 주고, 10일 후의 비트코인 가격 변동을 예측합니다. 이 모델은 텍스트 데이터의 임베딩을 생성하는 Twitter-RoBERTa, BERT-MNLI 모델과 Transformer Encoder 기반의 암호화폐 시장 임베딩 데이터를 MLP로 결합함으로써 구현하였습니다.
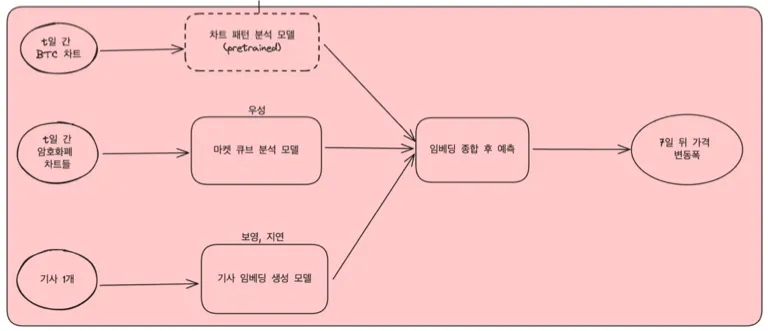
Model Pipeline. 차트 패턴 분석 모델은 이번 프로젝트에서 사용하지 않음.
텍스트 데이터 임베딩 생성 모델
Twitter-RoBERTa
해당 모델은 Google이 2018년 제안한 수정된 BERT 모델인 RoBERTa에 기반을 둔 감정 분석 모델입니다. 총 ~58M개의 트윗 데이터로 학습되고 TweetEval benchmark으로 평가하여 미세 조정된 모델로 주어진 텍스트가 부정적인지, 긍정적인지 임베딩을 추출하여 학습에 사용하고자 하였습니다.
BERT-MNLI
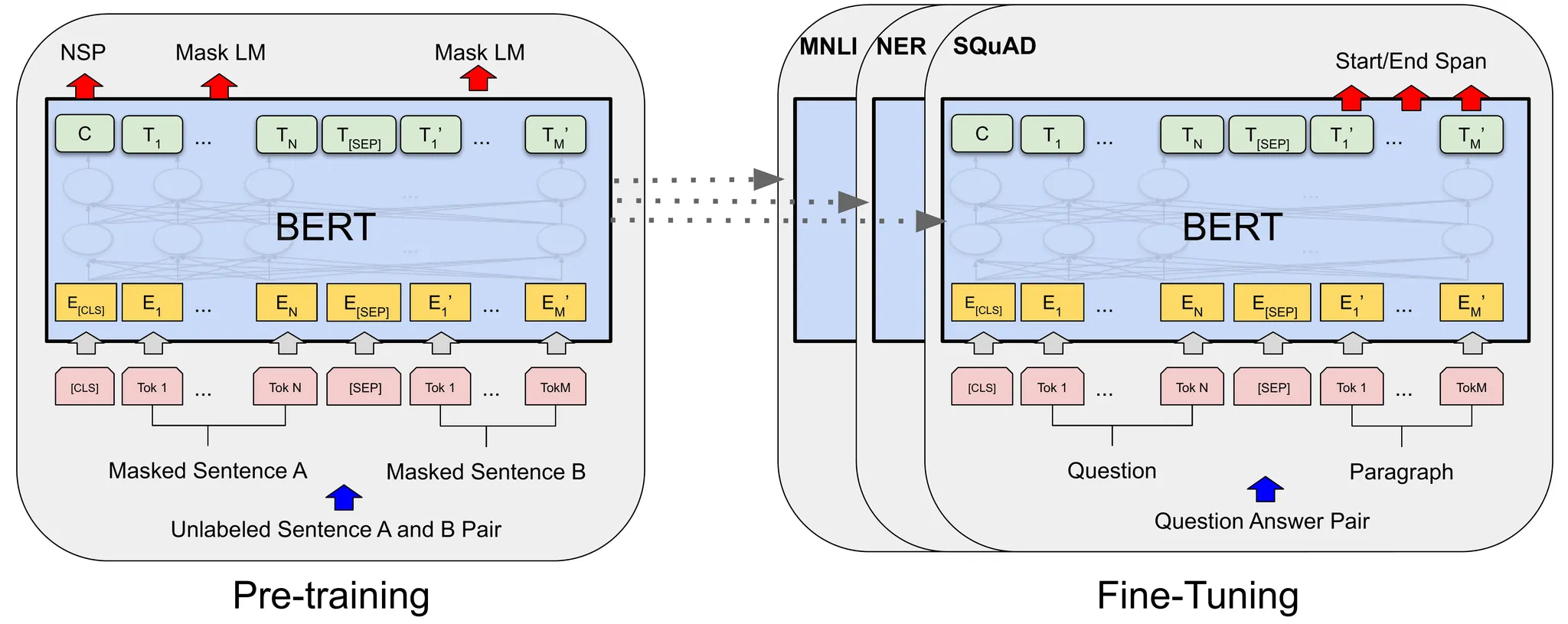
BERT 모델
MNLI는 Multi-Genre Natural Language Inference의 약자로 자연어 추론 태스크 중 하나입니다. BERT-MNLI 모델은 BERT 기반의 MNLI 모델로 가설과 텍스트 데이터를 함께 입력하면 주어진 가설이 텍스트 데이터에 대해 논리적으로 들어맞는지 판단합니다. 사용할 텍스트 데이터셋이 영어이므로 "The Bitcoin Price is likely to continue rising.” 이라는 가설을 함께 제시함으로써 비트코인 가격이 주어진 텍스트에 긍정적 영향을 받는지, 부정적 영향을 받는지 그 임베딩을 반환하도록 하였습니다.
암호화폐 시장 임베딩 데이터 생성 모델
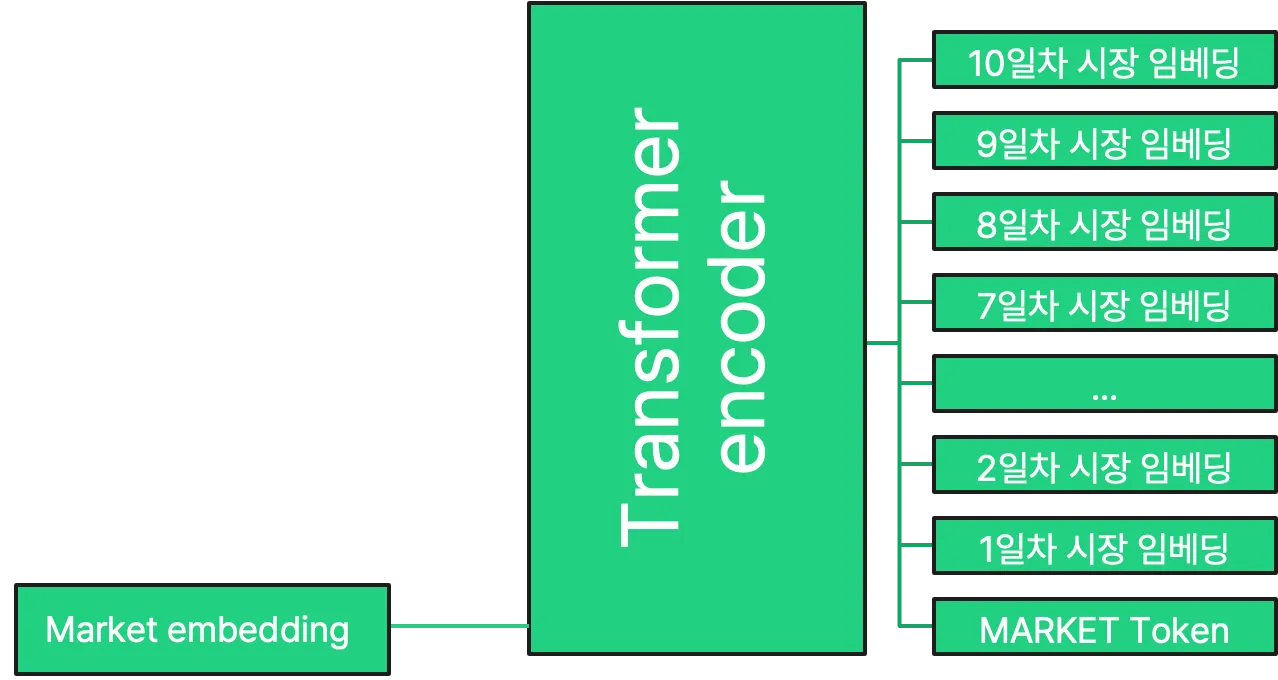
해당 모델은 Transformer Encoder 구조로 구현되었습니다. 우선 암호화폐 시장 상황을 3차원 큐브 형태로 만들어, conv2d를 통해 각 날짜별 시장 상황에 대한 임베딩을 생성합니다. 여기에 위치 임베딩을 추가하여 시퀀스 벡터를 얻어 표준 transformer encoder에 입력함으로써 임베딩을 생성합니다. 예측을 수행하기 위해 시퀀스에 추가적인 학습 가능한 "예측 토큰"을 추가하는 표준적인 방법을 사용하였습니다.
임베딩과 MLP
위에서 생성된 텍스트 데이터에 대한 임베딩과 암호화폐 시장에 대한 임베딩을 MLP에 입력하여 10일 후의 비트코인 가격 변동을 예측할 수 있도록 하였습니다.
실험 결과
모델 학습 후 테스트 결과
다음과 같은 하이퍼파라미터를 설정하였을 때 가장 좋은 성능을 보였습니다.
Market Cube Embedding Size | 512 |
Optimizer | Adam |
Learning Rate | 1e-5 |
Betas | (0.9, 0.98) |
eps | 1e-8 |
Accuracy (오차 범위 0.1%p) | 93.5% |
학습 데이터 종류별 성능
오차 범위 | 0.1%p | 0.01%p |
뉴스 + 마켓 | 93.5% | 15% |
마켓 | 93% | 13.5% |
뉴스 | 70% | 8% |
경향성까지는 학습이 가능하지만 좋은 성능이라고 보기엔 애매한 정확도를 확인할 수 있었습니다.
결론
프로젝트 결과 분석
오차 0.1%p로 가정 시 정확도 93%
하지만… 오차 0.01%p로 가정 시 정확도 15%
개선 방향
이번 프로젝트에서 사용하였던 것과 같은 접근 방법으로 지수 추종 인덱스 펀드의 가격 변화를 예측하는 태스크도 해볼 수 있을 것 같습니다. KOSPI 200나 QQQ에 대해 학습하고, 코스피 종목 가격 변화 또는 나스닥 종목 가격 변화 데이터를 학습한다면 비트코인보다 실용적인 뉴스 기반 주식 가격 예측 프로덕트를 만들 수 있으리라 생각합니다.
보완 필요 사항
프로젝트를 진행하며 아쉬움을 느꼈던 부분은 대체로 시간과 관련된 사항들이었습니다.
모든 팀원이 딥러닝 프로젝트를 처음 해보는 것이었기에 초반에 계획을 너무 루즈하게 설정했던 것이 프로젝트 수행에 있어 아쉬움으로 남습니다. 기존 계획에 따르면 비트코인 차트 패턴에서 임베딩을 추론해내는 모델을 하나 더 사용했어야 하지만 구현 상의 어려움과 시간 문제로 포기한 것이 아쉽습니다. 모델 구현에 있어 시간을 충분히 더 들였다면 학습이 용이한 모델을 발견할 수 있었으리라 생각됩니다. 양질의 데이터도 중요하지만 데이터를 준비하는 시간이 너무 길어서도 안 된다는 점을 깨닫게 되었습니다.
