오목의 달인 
소개
복잡한 규칙과 방대한 경우의 수를 가진 게임에 있어 AI가 고성능 하드웨어와 오랜 시간을 필요로 한다는 한계점을 개선하기 위해 진행된 프로젝트입니다.
[알파제로(AlphaZero)의 강화학습 기법을 활용한 오목 AI ]
•
기보 데이터와 self-play를 결합한 효율적인 학습 진행
•
MCTS 병렬화 기법을 도입해 탐색 속도 개선
•
렌주룰을 적용해 실제 오목 대국과 비슷한 환경 구현
•
콘솔을 통해 ai와 실제 플레이 가능
방법론
1.
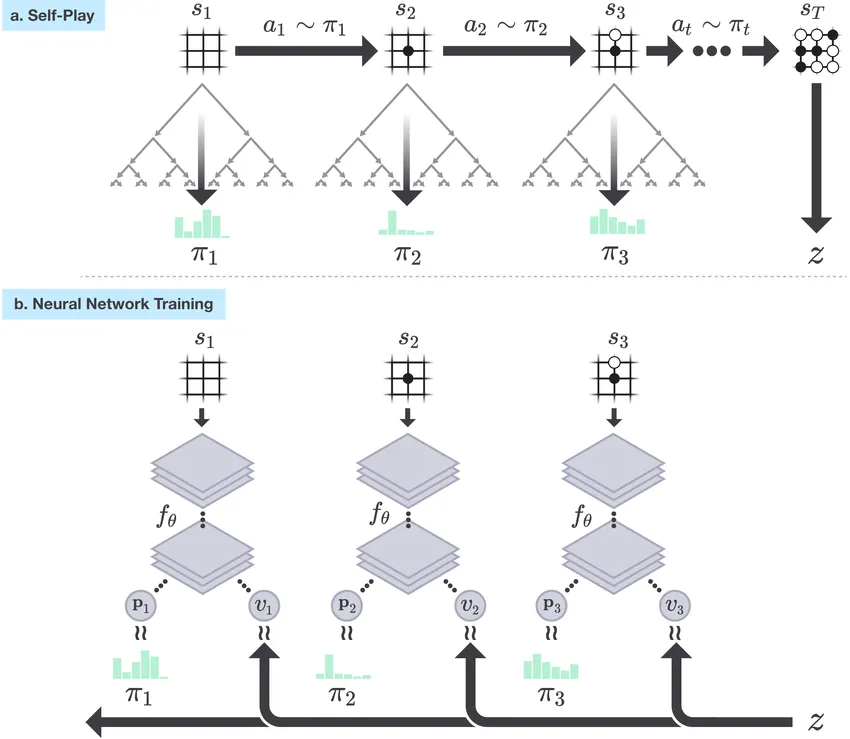
알파고, 알파제로 참고
•
알파고: MCTS 기반으로 작동합니다. Policy Network로 탐색 범위를 줄이고, Value Network로 가치를 평가하여 효율적으로 경우의 수를 탐색
•
알파제로: Policy Network과 Value Network을 하나의 네트워크로 통합
2.
3.
병렬화(Parallelization)
•
MCTS의 탐색 횟수가 기하급수적으로 증가하는 문제를 해결하기 위해 스레드를 활용해 병렬 탐색 진행
4.
데이터 준비 및 학습
•
약 10만 개의 오목 대회 기보를 여러 조건에 따라 필터링하여 학습 데이터로 사용
•
이 데이터를 통해 초기 모델을 학습시킨 후, self-play를 통해 추가적인 학습을 진행
환경 설정
pip install -r requirements.txt
Plain Text
복사
사용 방법
1.
학습
python3 main1_fromdata.py
Plain Text
복사
1.
오목 게임 플레이
python3 tmp_userplay.py
Plain Text
복사
예시 결과
(영상으로 대체)
팀원
•
문승기: 문제정의, 데이터셋 수집, 코드 작성
•
윤혜원: 코드 작성, 데모 개발
•
임주원: 코드 작성, 데모 개발
•
문정민: 코드 작성, 데이터 전처리
•
신동현: 코드 작성, 데이터 전처리
